 Enterprise GIS web application development is about how to represent your existing data and how to capture new data. Here at Farallon, we have successfully built some very smart geospatial web applications that guide the user in that process.
Enterprise GIS web application development is about how to represent your existing data and how to capture new data. Here at Farallon, we have successfully built some very smart geospatial web applications that guide the user in that process.
This post is about how we support the backing up of data for these advanced geospatial apps in order to facilitate the web app development life cycle as well as the production life cycle.
In the early years of GIS web development at Farallon, it was easy to do (or not do) data backup since most projects were single iterations. As the sophistication and mission-critical nature of GIS web apps grew, we starting working on projects that involved multiple iterations, with different developers working on different items of the application/database concurrently.
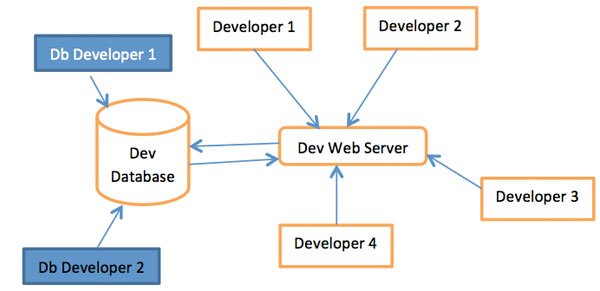
The above diagram represents the initial architecture to support projects that had multiple iterations.
The steps followed for every iteration were:
- Apply schema and data changes to the database
- Check in the changes as sql files into source control.
- Publish the changes to the server side developers so that they know how to interact with the data e.g. ERD diagram
- Once the iteration is complete label it as such in source control so that there is stable db version that we can roll back to for that iteration.
In the above architecture it’s very clear that schema/data integrity become very important so that developers can concentrate on what they are working on and not worry about the application breaking down or not working correctly due to discrepancies in its source (the database).
For example let’s take this scenario from our archaeological sites management system.
Let’s say there is are three tables: Entity with EntityId, Name and Type as the three columns; EntityGeometry with GeometryId, EntityId, Geometry; and mapping table called EntityAddress with StreetNo, StreetName, City, State and Zipcode.
Developer 1 is responsible for building a web form to fill the Entity and EntityGeometry tables. Developer 2 is responsible for creating the web form to enter the EntityAddress table.
Let’s say there is a new requirement for the Entity table schema to include a creation date and retirement date. So the db Developer goes in and adds creation and retirement dates, making them non-null. Developer 1 works on adding the creation/retirement dates to the webform.
It’s needless to say that you will have to first add an Entity to the database before you can add an EntityAddress to that Entity. So if Developer 2 tries to test his code for a new Entity, it will break since the webform in source control doesn’t have the EntityAddress yet but the database does.
From the above scenario it’s clear that the above architecture has its flaws.
In order to resolve that issue a replica of the dev environment was created in each of the developer’s development box.
To maintain schema/data integrity schema changes were maintained as .sql files and data was maintained as .dat files in source control. Deployment scripts were created to facilitate the process of backing up schema/data with one click to a bat file.
Lets look at the archeological site management scenario with this new model.
- Db Developer can now make the schema change and data change and run the bat file to back up the changes to the schema/data and check it in to source control.
- Developer 1 can do the update, run the dat file to restore the new schema and data and work on updating the web form to contain the EntityAddress information.
- Developer 2 can wait until Developer 1 completes the web form changes before he gets the latest from source control for both the db and web form changes thus allowing him to test his code without issues.
Some other advantages of the above model are that:
- Developers can, with lots of freedom make changes to the data to test multiple scenarios for the component they are building.
- By separating the dat files into development and production versions it makes it easy to maintain pristine data of the end users without worrying about it during iterations.
Hopefully I was able to convey how this new model has made both the database and server developers life easier. In the next couple of blogs I will take about specific implementations for Postgres and Sql Server.



